ReconDreamer-RL: Enhancing Reinforcement Learning via Diffusion-based Scene Reconstruction
- Chaojun Ni*1,2
- Guosheng Zhao*1,3
- Xiaofeng Wang*1
- Zheng Zhu*1✉
- Wenkang Qin1
- Xinze Chen1
- Guanghong Jia4
- Guan Huang1
- Wenjun Mei2✉
- 1 GigaAI
- 2 Peking University
- 3 CASIA
- 4 Tsinghua University


Abstract
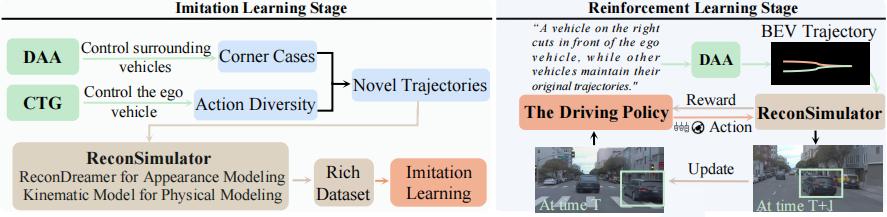
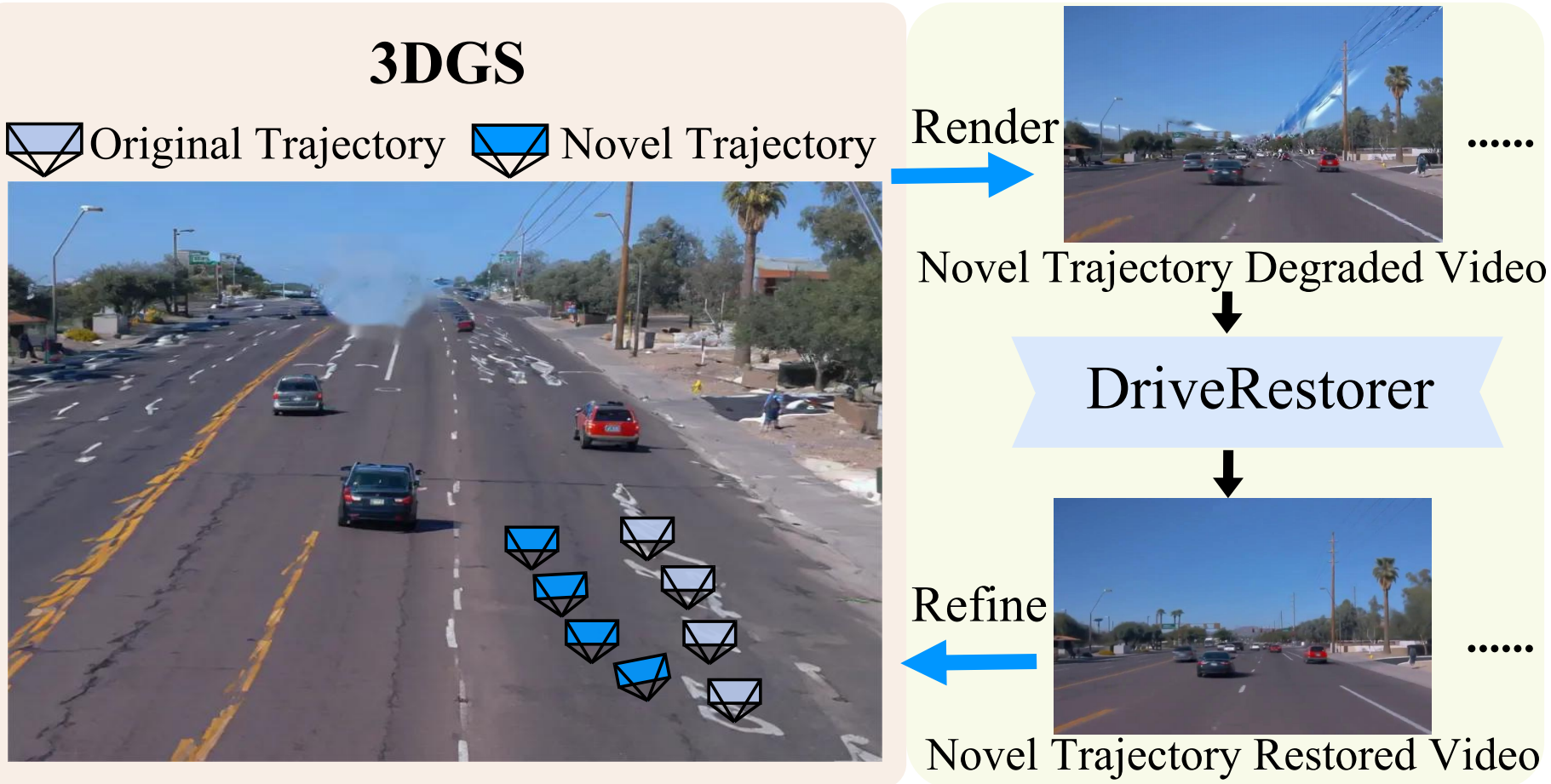
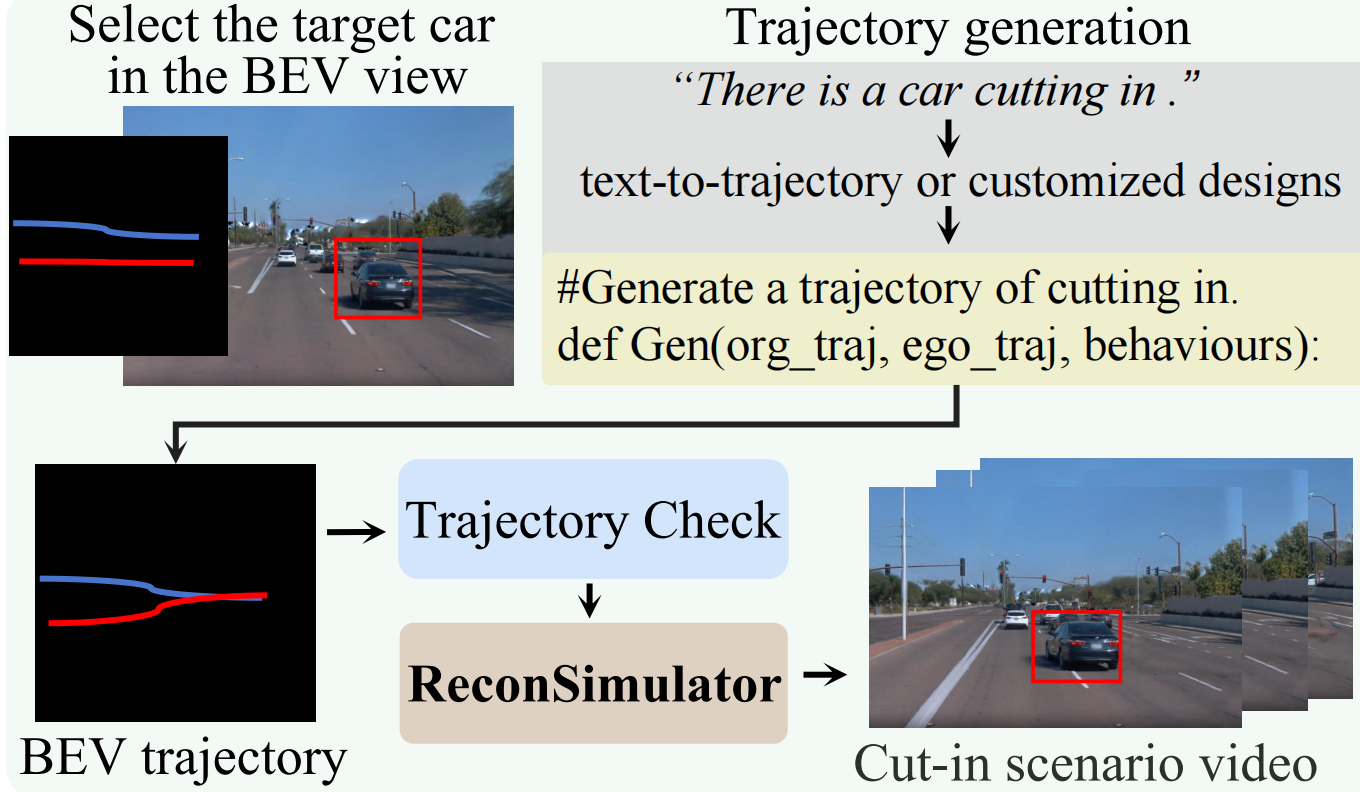
Reinforcement learning for training end-to-end autonomous driving models in closed-loop simulations is gaining growing attention. However, most simulation environments differ significantly from real-world conditions, creating a substantial simulation-to-reality (sim2real) gap. To bridge this gap, some approaches utilize scene reconstruction techniques to create photorealistic environments as a simulator. While this improves realistic sensor simulation, these methods are inherently constrained by the distribution of the training data, making it difficult to render high-quality sensor data for novel trajectories or corner case scenarios. Therefore, we propose ReconDreamer-RL, a framework designed to integrate video diffusion priors into scene reconstruction to aid reinforcement learning, thereby enhancing end-to-end autonomous driving training. Specifically, in ReconDreamer-RL, we introduce ReconSimulator, which combines the video diffusion prior for appearance modeling and incorporates a kinematic model for physical modeling, thereby reconstructing driving scenarios from real-world data. This narrows the sim2real gap for closed-loop evaluation and reinforcement learning. To cover more corner-case scenarios, we introduce the Dynamic Adversary Agent (DAA), which adjusts the trajectories of surrounding vehicles relative to the ego vehicle, autonomously generating corner-case traffic scenarios (e.g., cut-in). Finally, the Cousin Trajectory Generator (CTG) is proposed to address the issue of training data distribution, which is often biased toward simple straight-line movements. Experiments show that ReconDreamer-RL improves end-to-end autonomous driving training, outperforming imitation learning methods with a 5× reduction in the Collision Ratio.